These days, the typical website or mobile application pulls in data from a variety of sources. Places such as social media networks, multimedia providers, mapping tools and online retailers being prime examples. Together, these items combine with our own content to create a compelling user experience.
Getting data from these disparate places can be a challenge. Each has their own API, which comes with the requisite learning curve. Not to mention all of the maintenance tasks that can waste precious time. And the more services you harvest data from, the more complicated your job becomes. Pretty soon, you are swimming in a tangled mess of code.
The question is: How can you simplify the process?
The answer is by utilizing scrapestack, of course. This real-time, scalable proxy and web scraping REST API can help you get the data you need – easily and reliably.
Sound like a lifesaver? Here’s a look at what it can do for you.
A Powerful Web Scraping Engine
Scraping is an incredibly useful way to bring data into your application. You can use it for everything from listing your tweets to parsing product reviews from Amazon or getting your current Google ranking.
scrapestack was built to handle all of your scraping requirements in one easy-to-use place. That means no more running around, trying to figure out various APIs. Instead, take advantage of these powerful features:
Automated Solutions for Technical Challenges
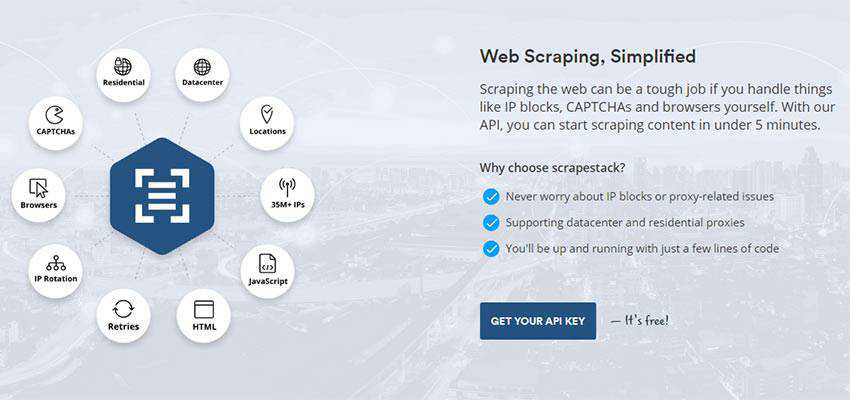
Harvesting data at scale can be difficult. You often run into technical issues such as IP addresses being blocked or having to deal with CAPTCHA responses. scrapestack has built-in solutions to keep content flowing smoothly.
For example, their pool of 35+ million datacenter and residential IP addresses from across the globe allow for features such as IP rotation and smart retries. You can also scrape from over 100 global locations or use random geo-targets.
As for those pesky CAPTCHAs, scrapestack can help you there as well. They’ll be taken care of automatically.
Built for High Speed and Volume
Web scraping requires a robust infrastructure to ensure that data gets where it needs to go – and quickly. With over 1 billion requests handled monthly and 99.9% average uptime, scrapestack has been built for reliability.
It’s also blazing-fast, with the ability to scrape millions of web pages in mere milliseconds. Plus, it can serve up concurrent API requests. All the performance and stability you need is baked right in.
Access to Full Page Content – Including JavaScript
With scrapestack, you’ll get the full HTML content of a web page – including JavaScript rendering. It’s everything you would find in a web browser, all within a JSON response. Just enter in a valid URL to get started.

Fast Integration
scrapestack’s API was designed to handle all of the most difficult tasks for you. And it’s extremely well documented. The result is that you can be up and running in as little as five minutes. All it takes is a few simple lines of code.

Start Using scrapestack for Free
Data harvesting doesn’t have to be so complicated. scrapestack has the infrastructure, features and flexibility you need to efficiently scrape web pages. It opens the door to an almost limitless array of content possibilities.
And they also have plans to fit all budget and data requirements. In fact, you can get started for free.
So, grab your free API key and see all of the benefits scrapestack has to offer. You can easily upgrade as your needs change.
You might just be amazed at how quickly and easily you can scrape content from anywhere.
Related Topics
Top